In my full-time role at Nuvi, I’ve been lucky enough to work on a team where we’re able to push the boundaries in the natural language processing field. We built out several different “facets” that we score text on, including sentiment, emotion, vulgarity, tense, and currently, we’re working on promotion detection.
While the technical side of NLP is hard, one of the hardest things was unexpected - defining the boundaries between the categories in question. Which words count as vulgar? Does anticipation entail positive emotions? Can a single tweet exude anger and fear at the same time despite being opposites according to Plutchik? In this article, we’ll explore some of these questions and how we ended up answering them.
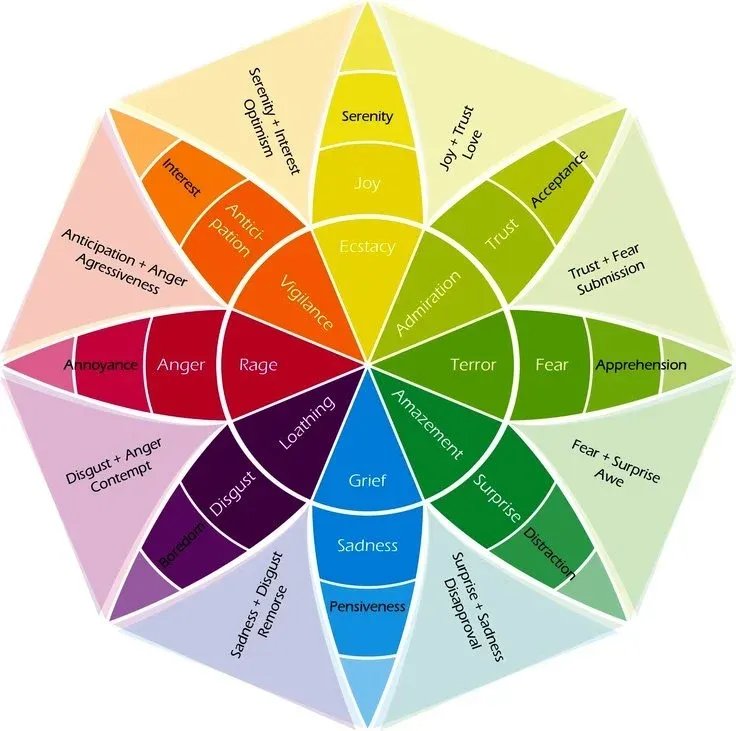
Emotion Facets 🔗
The eight emotions we set out to build a classification engine for are defined by Plutchik’s wheel:
- Anger
- Fear
- Joy
- Sadness
- Trust
- Disgust
- Anticipation
- Surprise
Our emotion detection is based on a probabilistic algorithm that requires training and test data from human-annotations. To get a high-quality dataset, we found early on that simply telling our annotators to categorize sentences as to whether or not the author was expressing “anticipation” wasn’t nearly enough instruction. Once we got down to the brass tacks of some specific examples, we found that we didn’t even agree internally on classifications in many instances.
Let’s look at some of the examples we had trouble with as a team and go over the conclusions we came to. If you have thoughts be sure to tweet at me and let me know what you think.
Keep in mind that the definition of anticipation according to Oxford is “The action of anticipating something; expectation or prediction.” In other words, we’re looking for when someone is showing forethought, making a prediction, etc. Here are some examples we agreed on quickly as expressing “anticipation”:
- “I can’t wait to go to the movie theater again!”
- “I’m so excited for sports to come back, can’t happen soon enough!”
- “Tesla stock is way too high, it’s going to tank soon.”
The first one we had trouble with was:
I’m so nervous to go back to the office. Working from home has been great.
Some of us had the idea that “anticipation” carried a connotation of “being excited”. In other words, you can’t really anticipate something if you don’t want it to happen. We eventually decided that this isn’t a useful definition for several reasons. First, we already do sentiment classification separately, so baking positive sentiment into the anticipation facet isn’t super helpful. Second, the opposite of anticipation in our emotion wheel is “surprise”. We all agreed that surprises can be good or bad. It stands to reason the surpise’s opposite, anticipation, should behave the same way.
The next problematic example arose a few days later:
I don’t know if I’m going to win
One of my teammates made the point that this sentence expresses apprehension, which can be considered a form of anticipation. I played devil’s advocate saying that “I don’t know” is the polar opposite of a prediction, how can that be anticipation?
In the end, we found that we had to provide paragraph-long explanations of each category to our annotators, complete with examples of what is and isn’t counted as a part of the category in question.
Vulgarity Detection 🔗
NSFW Disclaimer: I’m going to talk about our vulgarity detection, and will need to say some naughty words. If you find that offensive turn back now!
The way the current iteration of our vulgarity engine works is to take a piece of text as input, for example:
“Well hot damn those potatos hit the spot!”
And output a fractional score from 0-1 representing how likely the text is to contain vulgar text. For the above sample, it might be something like .75 Which brings us to our first problem, what do we consider to be vulgar?
According to one of my teammates “damn”, “shit” and “hell” aren’t bad words. However, while he may not consider them to be, many people do. We’re left in the interesting position of trying to rank all the vulgar words. Here are some of the biggest issues we ran into with vulgarity:
Not all bad words are created equally 🔗
Most people would loosely agree with the following ranking from most vulgar -> to least vulgar :
- Fuck
- Bitch
- Shit
- Damn
- Hell
Religious / Culture Specific 🔗
However, problems arise when people of different religious beliefs examine the list. A Christian person may consider the following list accurate:
- Fuck
- Bitch
- Jesus Christ!
- Oh my God!
- Shit
- Damn
- Hell
Whereas the atheist/agnostic/pagan may not consider “Jesus Christ!” or “Oh my God!” to deserve to be on the list at all.
Geographically Specific 🔗
If you’re from England proper, you may also expect a few additional words:
- Fuck
- Wanker
- Bitch
- Shit
- Bloody
- Damn
- Hell
In the end, we ended up mixing the concept of probability and intensity for the sake of simplicity and we’ve found that our clients are happy with the result. For example, the presence of an intensely “bad” word that’s recognized by basically everyone as vulgar will have a higher weight in the probability calculation than one which is weaker or not accepted by everyone as “bad”.
vulgarity_weight = intensity * acceptance
Once we started looking at everything as a fluid spectrum it became much easier to agree amongst ourselves what constitutes “vulgarity”. My coworker who claimed “shit”, “damn”, and “hell” aren’t vulgar easily admitted that they’re more vulgar than trivial interjections like “crap”, “dang”, or “heck”.
Promotion and Solicitation Detection 🔗
The project we’re working on currently has also turned out to be a vague and difficult one to pin down. The goal is to classify text as to whether it’s promotional or not, but we’ve had a hard time defining what we want. For example, we all agreed quickly that the following we classify as :promotional":
- “We are doing a sweet promo this week! Sign up for 20% off”
- “Our new product just launched, be sure to check it out”
- “GORGEOUS 😍 previously owned Gucci backpack for $1700😍😍 ⭐️WE SHIP ⭐️ Call the store to purchase 555-555-5555 📲”
The following however posed an interesting problem:
Do I want a $42 @gucci lipstick yes I do…. can I afford it right now No I cant but it’s soooo good!!!!!!!
While it’s obviously promoting Gucci, it isn’t actually soliciting direct action from the reader. There’s no call to action. Is this a requirement of a solicitation as scored by Nuvi? We’re not sure yet - but we’re figuring that out.



